TopScan has an Export to CSV that I often use, I agree it would be very useful if there was also an Import.
My method is not “code free” but it is mostly generated. Define the CSV File in the DCT (see import below). The DCT lets you browse file to see its right. For a 1 time convert use the DCT conversion, or if you’ll be doing this often…
In an APP generate a Process to Read the CSV and Add to the TopSpeed. You’ll have to code those assignments and convert types. To help you can wizard a Browse / Form of the CSV file to view it before import. I made an example
Use the Import Tables in DCT to aid in defining the CSV file.

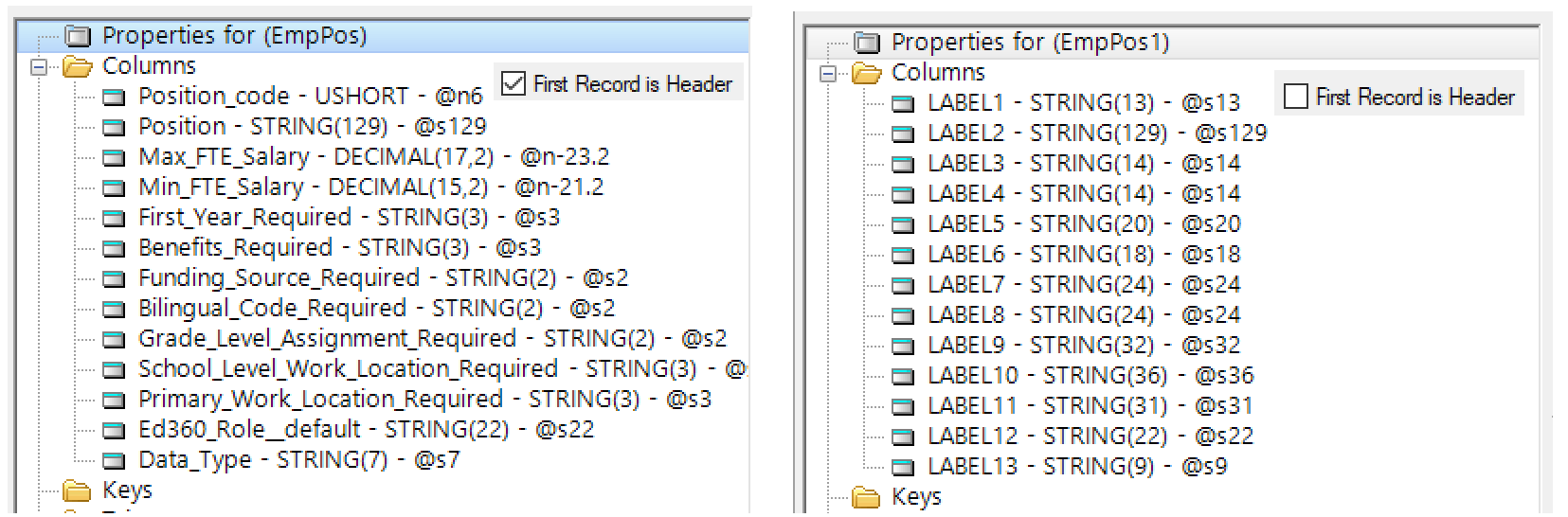
The import does a good job of picking types but you’ll need to review them. If you don’t check “First Header” the field names will be LABEL1,2,3… All the data types will all be STRING and the size will be increased to fit the Header label. E.g. “Benefits Required” is Yes/No so is sized as STRING(3) with Header checked but without STRING(18).
You will want to change the File’s FileName property because it will have the path picked in theimport wizard C:\xxxx\xxx\file.csv.

Now you have the CSV File and in an APP you can generate a Process to read it and add code to write your TPS.
If this is just a 1 time conversion you can use the DCT Conversion. Right-click on the TPS file and choose “Generate Conversion Program”, then pick From Table, then Pick the CSV file. It can do a “Code Free” Auto Convert if your column names match.