Are you about trigonometric functions in FPU or about implementation of them using SSE2 instructions?
Perhaps both. I don’t know. My assembler skills are only for the S/370 architecture, rather than the x86 architecture:)
The “fast” (without checking input parameter and processor flags after execution) FPU variant was here: Trigonometric functions are very slow - #16 by also
The SSE2 implementation is quite long. The beginning for sin() looks as follows:

Hi Mark,
GPUs would do these calcs in a time near zero, because of the high degree of paralellism they have. I’m reading they can calculate a sine in one cycle!
But to to reach the better performance, one would need to build a program with full algorithm (loop x, y’s) and load it with the datasets on the GPU, then run it. It wouldn’t worth to have a GPU program that just receives a number, calculate its sine and returns the result to your Clarion program running the LOOPs on CPU.
The MsVCRT.DLL has some functions to calculate sine and cosine. It is a Windows internal dll. VC runtimes MSVCR###.DLL also has a couple of them.
Here it can be seen those functions:
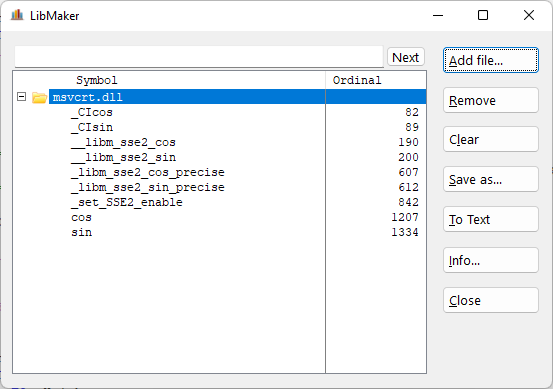
sin/cos are functions you could call directly with Clarion with the prototype: CSIN(REAL),REAL,C,NAME(‘sin’)
_CIsin/_CIcos are similar but expects the parameter already on st(0) register, it would be something like CCISIN(),REAL,C,NAME(‘_CIsin’) but previous to the CALL the angle parameter has to be on st(0) and it doesn’t happen that way in usual Clarion code, so it would need a wrapper function to accomodate the parameter.
The previous four functions works different depending on the state defined by the function _set_sse2_enable (0 or 1).
The other four functions
__libm_sse2_sin
__libm_sse2_cos
_libm_sse2_sin_precise
_libm_sse2_cos_precise
works only with SSE2 and instead of st(0) looks for the parameter on SSE2 register xmm0 and return the value there too, so would need a wrapper to call it from Clarion and Topspeed Assembler doesn’t seem to recognize those instructions and registers, but it can be done with their bytecodes.
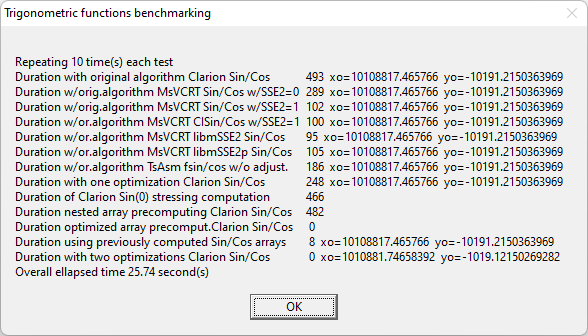
I found no difference on the accuracy of the eight functions in Mike’s example.
Here there is the previous test project shared but updated with Alexey’s one instruction fsin/fcos neat code and in his assembly module I added the wrappers for the other functions.
Here it can be seen a speed comparison:
trigtst2.zip (3,2 KB)
“What’s your sine”? is actually a good question nowadays. ![]()
2 Likes