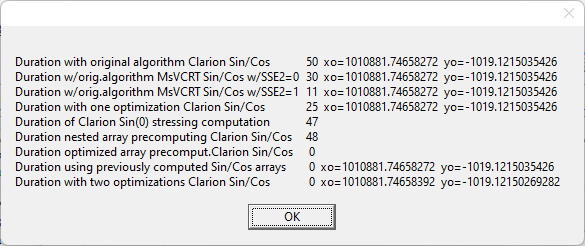
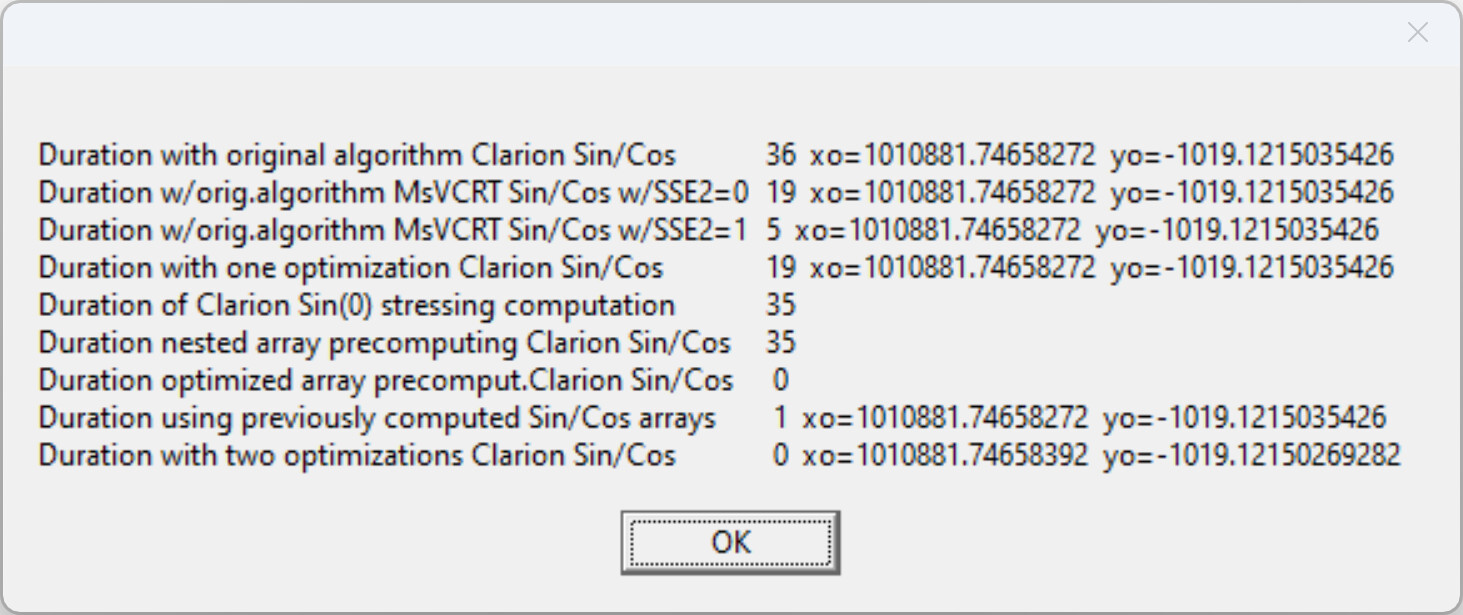
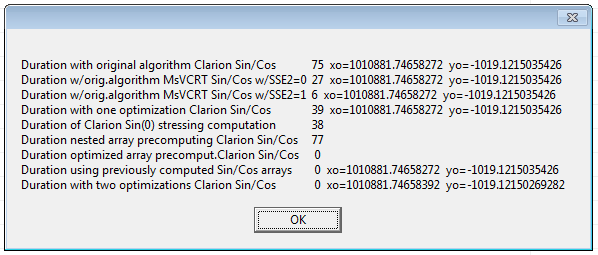
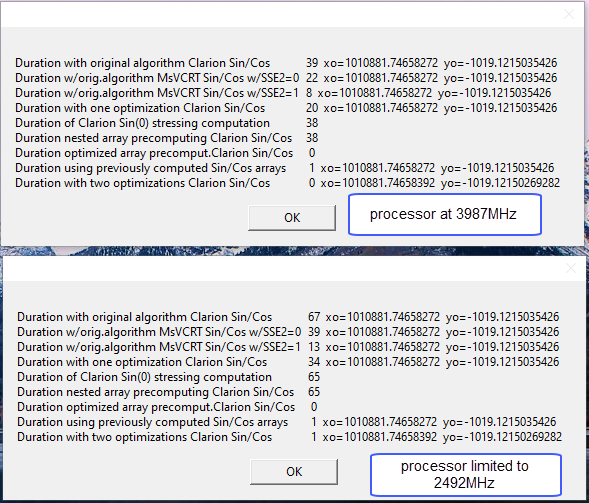
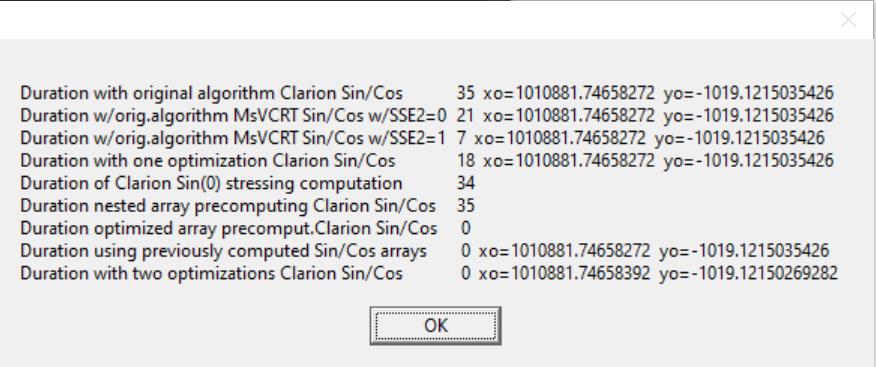
This Clarion code takes 800 milliseconds on my machine.
nWidth = 1920
nHeight = 1200
Pi2_128 = 2.0 * 3.1415 / 128.0
nWave = 15
xo = 0
yo = 0
LOOP x=1 TO nWidth
LOOP y=1 TO nHeight
xo += nWave * SIN(Pi2_128 * y)
yo += nWave * COS(Pi2_128 * x)
END
END
Same c# code takes 168 ms (~5 times faster):
for (int x = 0; x < nWidth; ++x)
for (int y = 0; y < nHeight; ++y)
{
xo += ((double)nWave * Math.Sin(2.0 * 3.1415 * (float)y / 128.0));
yo += ((double)nWave * Math.Cos(2.0 * 3.1415 * (float)x / 128.0));
}
It is a real example of image processing (the image is 1920x1200, each pixel is processed), When c# program does the job in a flash, the Clarion app hangs for seconds.
Hi Mike,
On my machine it lasts for 500 ms aprox, this code too:
LOOP nWidth * nHeight * 2 TIMES
DummyReal = SIN(0)
END
By looking at the debugger is seems they do several preparation steps. A workaround could be to precompute the values. The example you posted doesn’t need nested loops either but I imagine it is just an example.
PROGRAM
MAP
END
StartTime LONG
nWidth LONG
nHeight LONG
Pi2_128 REAL
nWave REAL
xo REAL
yo REAL
x LONG
y LONG
CODE
nWidth = 1920
nHeight = 1200
Pi2_128 = 2.0 * 3.1415 / 128.0
nWave = 15
xo = 0
yo = 0
StartTime = CLOCK()
LOOP x=1 TO nWidth
LOOP y=1 TO nHeight
xo += nWave * SIN(Pi2_128 * y)
yo += nWave * COS(Pi2_128 * x)
END
END
MESSAGE(CLOCK()-StartTime)
Calculations of sine and cosine are just 1 FPU instruction. The Intel documentation states that FSIN and FCOS instructions require that value in the ST(0) register must be in range -2^63…+2^63. Therefore, implementation of SIN and COS functions reduces passed argument to this range. Also, it resets the FPU state flags to check/clear possible error state.
Just tested in the debugger this expression: xo = SIN(0). xo is declared as REAL.
It takes 127 asm instructions: one of ClaRUN.dll:Cla$SIN call and 126 others.
The calculation of sine itself is the only assembler instruction: FSIN. The parameter of this instruction in ST(0) register must be in range -2^63…+2^63 => the SIN function must check parameter’s value and adjust it if it is out of this range. Execution of the FSIN instruction can raise #IS, #IA, #D, #P and #NM hardware exceptions => the SIN function must check the status after FSIN and reset flags in the command and status words to allow FPU continue to work. Plus it’s need to allocate the space on the stack to store original FPU status flags, to store data during adjusting the parameter, to store result of FSIN while checking/resetting the SPU status, etc.
The online help for Math.sin is too brief but description of this function in the MSDN Help covering .NET up to version 3.5 states:
Acceptable values of d range from approximately -9223372036854775295 to approximately 9223372036854775295. For values outside of this range, the Sin method returns d unchanged rather than throwing an exception.
IOW, .NET just does not part of work to check the passed angle value which CW RTL does.
I don’t know about NET3.5, I wasn’t born yet, but NET Framework 4.8.1 docs have this remark about Math.Sin:
This method calls into the underlying C runtime, and the exact result or valid input range may differ between different operating systems or architectures.:
Anyway thanks for the explanation, now I know why Clarion 5 times slower.
On my computer (old ThinkPad W530 with the i7-3840QM processor) the difference between CW and C# is less than 3 times: 59 sec/100 for CW and 227 ms for C#. After replacing SIN and COS with assembler functions imitating Math.Sin and Math.Cos (i.e., no actual parameter adjusting, no handling FPU status flags) the CW program became even slightly faster than C# one. It took 21 sec/100.
Here the assembler code for analogs of Math.Sin and Math.Cos:
module fastmath
segment FASTMATH_TEXT("CODE",00029H)
public __Sin:
fld st(0), qword [esp][4]
fsin st(0)
ret 8
public __Cos:
fld st(0), qword [esp][4]
fcos st(0)
ret 8
end
Prototypes of these functions in CW:
MODULE('FastMath.a')
_Sin (REAL),REAL,NAME('__Sin')
_Cos (REAL),REAL,NAME('__Cos')
END
What I wanted to point is that neither SSE nor SSE2 instruction sets have the “sine” function at all, which was, the way I understood it, implied by the question asked (“Why wasn’t the x87 instruction updated to use the implementation of the SSE2 instruction?”)
What exists are different libraries that calculate the “sine” better than fsin from x87 instruction set, and for all of these, it is actually not important that they use SSE or SSE2 – it is completely possible to implement the better sine algorithms with the basic x87 functions too, or with anything that doesn’t have SSE and SSE2. The effect of not having the sine function at all in SSE and SSE2 sets is that if you decide to use only these instructions for your x86_64 library, you have to implement everything with the basic instructions that you have, that is, you’d surely have to use some library code, even in the range in which fsin would suffice.
However, if the question was actually “why wasn’t the implementation of the x87 fsin instruction updated to be simply better” (which certainly could be implemented in the microcode) the answer is that apparently AMD tried exactly that with their K5 (1996) and then for the later processors had to revert to the “worse” to keep the compatibility with the existing programs, it is written in the original article or in the comments of it.