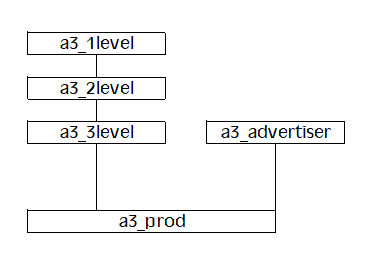
Here is the relationship diagram in simplified form:
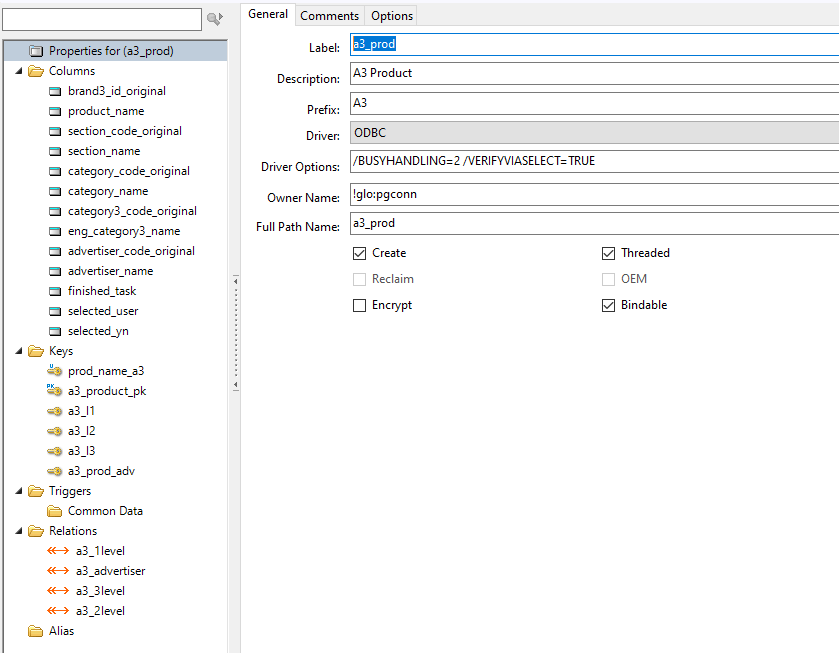
All the data is supplied in a 36MB CSV file, just for a3_prod. (products). I can infer the data in a3_advertiser (for example) because the PK field is included, as well as the description. Similarly with each of the other tables. Here is the structure of the a3_prod table:
Every table has its PK, description, and the last 3 fields shown here.
So I have a primary key on brand3_id_original (LONG) and an index on product_name (CSTRING 200)
Then I have an index for the foreign keys: section_code_original, category_code_original, category3_code_original, advertiser_code_original all LONG, being the primary keys of a3_1level, a3_2level, a3_3level and a3_advertiser respectively.
a3_advertiser has a PK of a3_advertiser_original (LONG), and an index of advertiser_name (CSTRING 200)
a3_1Level has a PK of section_code_original (LONG) and an index on section_name (CSTRING 200).
a3_2Level has a PK of category_code_original, (LONG) and an index on category_name (CSTRING 200). In addition it also has section_code_original with and index, and section_name, because it is a subsection of a3_1level. I know that section_name is redundant, since there is a relationship between a3_1level and a3_2level, but I have kept it there for convenience anyway.
a3_3level has a PK of category3_code_original, (LONG) and an index on eng_category3_name (CSTRING 200). In addition it also has section_code_original with and index, and category_code_original with an index, plus the section_name and category_name fields. a3_3level is a subsection of a3_2level.
So there are 5 tables and several relationships all going on at the same time. I originally wrote and tested the code using TPS files, and then later used FM3 to convert the structure to the ODBC linked tables in PostgreSQL (32bit UNICODE ODBC driver).
The full module is here:
importa3.clw (11.1 KB)
But for simplicity I will highlight the key parts:
UD.Debug('ImportA3 - loading CSV file')
if ~stfile.LoadFile('C:\dev\nielsen\Ariana3.csv') ! A3.csv ! Read the contents of the CSV file
MESSAGE('Error opening ariana3.csv')
else ! A3.csv
utstart = fmt.ClarionToUnixDate(today(),clock()) ! Start time
stETA = 'busy ...'
UD.Debug('ImportA3 - deleting old data')
a3_prod{PROP:SQL}='DELETE FROM a3_prod' ! Clean out the old data
a3_advertiser{PROP:SQL}='DELETE FROM a3_advertiser' ! Clean out the related a3_advertiser data
a3_3level{PROP:SQL}='DELETE FROM a3_3level' ! Clean out the related a3_3level data
a3_2level{PROP:SQL}='DELETE FROM a3_2level' ! Clean out the related a3_2level data
a3_1level{PROP:SQL}='DELETE FROM a3_1level' ! Clean out the related a3_1level data
OPEN(Progress) ! Open the progress window
UD.Debug('ImportA3 - splitting file')
stfile.Split('<13><10>') ! Records end with cr lf
ncount = stfile.records() ! Count the total number of records
UD.Debug('ImportA3 - ' & ncount & ' records')
i = 0
j = 0
LOOP ! Loop
i = i + 1 ! Current line number
stline.SetValue (stfile.GetLine(i)) ! Extract the line
count = ncount-i
DISPLAY(?Count) ! Update the countdown display
stline.split(',','"','"',true) ! Get all the CSV fields from the line
! Load the values into the relevant ariana3 fields
A3:section_code_original = stline.GetLine(1) ! LONG !Section Code Original
A3:section_name = stline.GetLine(2) ! STRING(200) !Section Name
This carries on for a bit while all the fields are populated. Then we do the 5 TryInsert commands
if A3:brand3_id_original > 0 ! Do we have a value?
if Access:a3_1level.TryInsert() = Level:Benign ! Try to insert the a3_1level record
!UD.Debug('ImportA3 - AL1 ' & CLIP(AL1:section_name))
end
if Access:a3_2level.TryInsert() = Level:Benign ! Try to insert the a3_2level record
!UD.Debug('ImportA3 - AL2 ' & CLIP(AL2:category_name))
end
if Access:a3_3level.TryInsert() = Level:Benign ! Try to insert the mp_3level record
!UD.Debug('ImportA3 - AL3 ' & CLIP(AL3:sub_category_name))
end
if Access:a3_advertiser.TryInsert() = Level:Benign ! Try to insert the a3_advertiser record
!UD.Debug('ImportA3 + A3A ' & CLIP(A3A:advertiser_name))
end
!UD.Debug('ImportA3 - A3 ' & CLIP(A3:product4_name))
if Access:a3_prod.TryInsert() = Level:Benign ! Try to insert the record
j = j + 1 ! Success
else
!UD.Debug('ImportA3 insert failed: ' & CLIP(stline.GetValue()))
UD.Debug('ImportA3 a3_prod insert failed: ' & A3:section_code_original & ',' & CLIP(A3:product_name))
end
else
UD.Debug('ImportA3 bad data: ' & CLIP(stline.GetValue()))
end
Then the loop is closed:
IF j % 1000 = 0 ! Every 1000 records
ut = utelapsed / (i * 1.0) ! seconds per record
UD.Debug('ImportA3 - ' & i & ' records, ' & ut & ' seconds/record')
END ! Every 1000 records
UNTIL i >= ncount ! Loop ! Try the next record
utelapsed = utnow - utstart ! Elapsed time
stETA = fmt.FormatValue(utelapsed,'@T4Z ') ! Elapsed time in HH:mm:ss format
UD.Debug('ImportA3 - ' & j & ' records imported out of ' & ncount & ', and ' & ncount-j & ' records dropped. Elapsed time: ' & stETA)
CLOSE(Progress)
MESSAGE(j & ' records imported out of ' & ncount & '<13><10>' & ncount-j & ' records dropped.<13><10>Elapsed time: ' & stETA) ! Report the results
end ! A3.csv ! All done
stline.Free()
stfile.Free()
So hopefully I have answered all the questions:
I did not try to get exclusive access, either in the TPS or ODBC version of the code.
I haven’t tried any transaction stuff.
I did not try to stop the program and restart it where I left off.
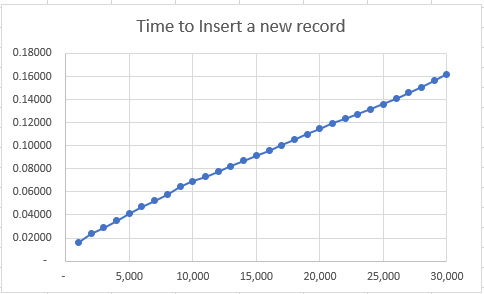
I am busy importing 241,486 records. The first 1,000 records averaged 0.012 seconds/record
By the time we got to 10,000 records it was 0.074 sec/record
at 70,000 records we are at 0.4965 sec/record
and by my calculations it will finish early on Wednesday morning. (I am writing this on Saturday evening) So far it has run for just over 12 hours. Do I just let it run or risk more delays in just getting the data inserted so I can carry on with the rest of the project?
I will try any suggestions if I have to run it again for any reason.
 Fortunately FM3 didn’t try to do an autonumber on the PG side, but I was still feeding PG garbage from the Clarion side. I didn’t notice it until I started looking at the actual data, because the PG data structure and indexes/constraints were exactly what I thought they should be.
Fortunately FM3 didn’t try to do an autonumber on the PG side, but I was still feeding PG garbage from the Clarion side. I didn’t notice it until I started looking at the actual data, because the PG data structure and indexes/constraints were exactly what I thought they should be.